Speeding Up Django Startup Times with Lazy Imports
At Fancer we are building the security suite for startups. Startups use a lot of SaaS tools and services which means we are building a lot of integrations. Most of these go through API calls but we also try to leverage SDKs to make our lives a little bit easier.
The problem we started noticing was that loading all these 3rd party integrations has made our Django app feel very sluggish. While this was noticeable around deployments and starting scans, it hurt the most during local development. It was taking around 10s to run ./manage.py check which meant that any Django command ended up being slow. Devs felt this the most with development server restarts and when running tests.
Finding the culprit
Since Python 3.7 there is a built-in tool to analyze how long each import takes: python -X importtime. The output can be several thousand lines long and kinda hard for a human to parse:
import time: self [us] | cumulative | imported package
import time: 121 | 121 | _io
import time: 25 | 25 | marshal
import time: 153 | 153 | posix
import time: 392 | 690 | _frozen_importlib_external
import time: 231 | 231 | time
import time: 141 | 372 | zipimport
import time: 32 | 32 | _codecs
import time: 352 | 383 | codecs
import time: 780 | 780 | encodings.aliases
import time: 1437 | 2599 | encodings
import time: 243 | 243 | encodings.utf_8
import time: 49 | 49 | _signal
import time: 20 | 20 | _abc
...
So Claude1 was tasked to parse it and report back which modules take the longest to import. A few seconds later we had our list:
self (ms) cumul (ms) module
------------------------------------------------------------
726.0 2277.1 google.cloud.asset_v1
717.3 793.3 google.cloud.osconfig_v1
696.2 697.1 google.api_core
667.5 687.0 google.pubsub_v1
655.1 720.0 google.cloud.orgpolicy_v2
327.5 358.2 google.cloud.monitoring_v3
148.9 155.9 snowflake.core.role._generated.api.role_api
146.2 184.9 snowflake.sqlalchemy.base
104.6 104.6 apps.integrations.gcp.datastructures
94.1 97.3 mypy_boto3_ec2.type_defs
93.8 93.8 apps.identity.filters
66.8 66.8 apps.integrations.azure.datastructures
56.6 58.5 google.cloud.orgpolicy_v2.services.org_policy.pagers
44.1 44.2 ua_parser_builtins.regexes
34.5 34.5 mcp.types
32.2 32.2 apps.integrations.aws.datastructures
28.6 30.0 snowflake.connector.description
21.9 21.9 apps.integrations.digitalocean.datastructures
19.6 69.0 apps.scanners.models
19.5 385.3 fastmcp
Making imports lazy in Python 3.15
Python 3.15, due to be released later this year, will have a built in way to make imports lazy thanks to PEP-810. Instead of:
from google.cloud.asset_v1 import AssetServiceClient
you write:
lazy from google.cloud.asset_v1 import AssetServiceClient
The lazy keyword defers the import until AssetServiceClient is first used instead of initial startup.
Making imports lazy pre Python 3.15
But unfortunately we don’t live in the future so we had to solve this problem the old-fashioned way. There are packages on PyPI that can help, but we decided to move the imports inline into functions where these modules are used. For type checking we moved the imports behind if TYPE_CHECKING: guard.
To make sure we don’t regress and reintroduce a slow top level import we configured the flake8-tidy-imports plugin to prevent certain top level imports.
[tool.ruff.lint.flake8-tidy-imports]
banned-module-level-imports = [
"snowflake",
"google",
"googleapiclient",
"kubernetes",
"fastmcp",
"mcp",
"sigma",
"mypy_boto3_ec2",
"mypy_boto3_s3",
"mypy_boto3_iam",
"mypy_boto3_rds",
"mypy_boto3_kms",
"mypy_boto3_eks",
"mypy_boto3_ecr",
"mypy_boto3_sqs",
"mypy_boto3_sns",
"mypy_boto3_lambda",
"mypy_boto3_guardduty",
"mypy_boto3_cloudtrail",
"mypy_boto3_accessanalyzer",
"svix",
"checkdmarc",
"openpyxl",
"pydantic_ai",
"user_agents",
]
And we explicitly ignore this rule in test files with # noqa: TID253 and a few other places.
Results
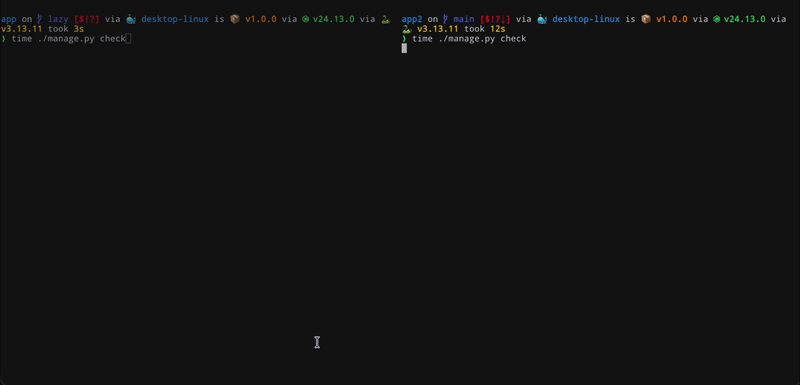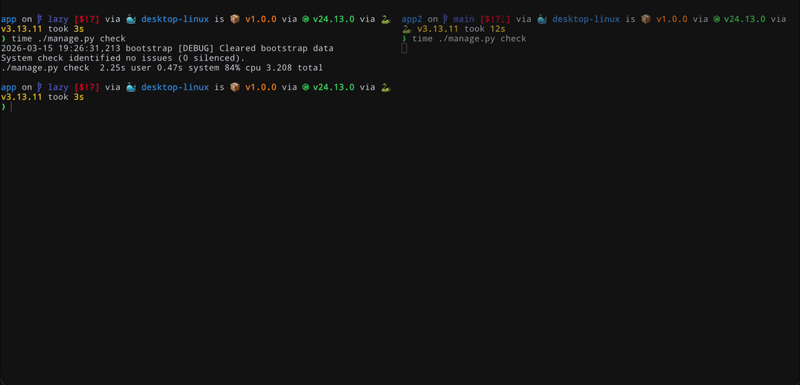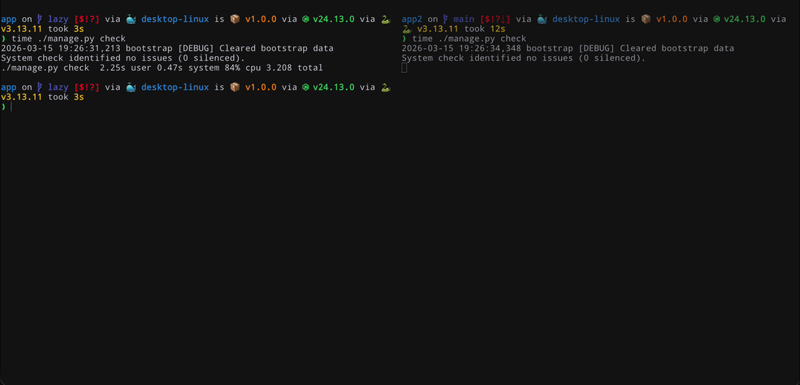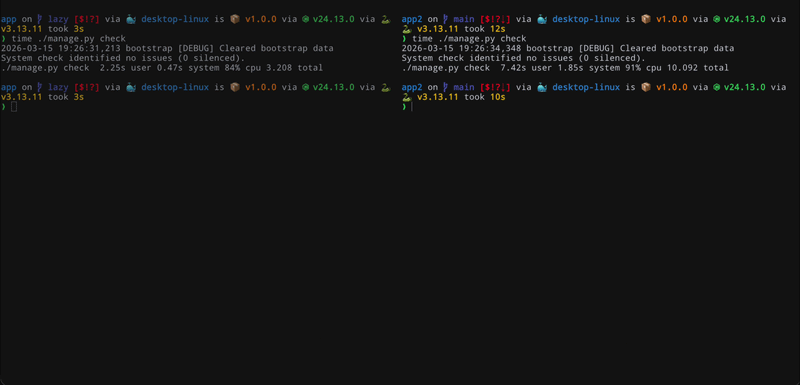
After some very tedious refactoring (mostly fueled by Claude tokens) we managed to get the baseline 9.45s to run ./manage.py check down to only 2.17s! Before and after look like night and day, here is the comarision again:
Caveat
The downside of this is that we now risk running a heavy import during the request/response cycle. Thankfully in our case we mostly only use the heaviest modules in Celery tasks so we don’t have to worry too much, but we will be keeping a close eye on p95 request times to make sure this doesn’t impact our end-users in any way.
If this does become a problem the common way to solve it in gunicorn is to use the post_worker_init hook and move the necessary imports there. This makes sure that the modules imported before the worker starts serving requests, making sure our users don’t see a slow request due to this!
Claude wrote this this script to parse importtime output into a human readable form:
↩︎""" Parse the output of `python -X importtime` and show the top slowest imports. Usage: python -X importtime manage.py check 2> import.log python scripts/parse_importtime.py import.log """ import sys def parse_importtime(path): entries = [] with open(path) as f: for line in f: if not line.startswith("import time:"): continue # Format: "import time: self [us] | cumulative | imported package" parts = line.removeprefix("import time:").split("|") if len(parts) != 3: continue try: self_us = int(parts[0].strip()) cumulative_us = int(parts[1].strip()) except ValueError: continue module = parts[2].strip() entries.append((self_us, cumulative_us, module)) return entries def main(): if len(sys.argv) < 2: print(__doc__.strip()) sys.exit(1) n = 20 if len(sys.argv) >= 3: n = int(sys.argv[2]) entries = parse_importtime(sys.argv[1]) entries.sort(key=lambda e: e[0], reverse=True) print(f"{'self (ms)':>10} {'cumul (ms)':>11} module") print("-" * 60) for self_us, cumul_us, module in entries[:n]: print(f"{self_us / 1000:10.1f} {cumul_us / 1000:11.1f} {module}") if __name__ == "__main__": main()